What Is Anchor Box In Yolo / Yolo is one of the most sucessful object detection algorithm in the field, known for its lightening speed and decent accuracy.
What Is Anchor Box In Yolo / Yolo is one of the most sucessful object detection algorithm in the field, known for its lightening speed and decent accuracy.. These 4 new neurons are the coordinates of the object present in the. Source code for each version of yolo is available, as well as as the weight file is loaded, you will see debug information reported about what was loaded, output the function returns a list of boundbox instances that define the corners of each bounding box in the. The idea of anchor box adds one more dimension to the output labels by. Notice that, in the image above, both the car and the pedestrian are centered in the middle grid cell. Yolo's anchor box requires users to predefine two hyperparameters what about shapes?
Confidence probability that there's some object for each of the anchor boxes predicted in each of the. In this tutorial, you'll learn how to use the yolo object detector to detect objects in both images and video streams using deep learning, opencv, and by applying object detection, you'll not only be able to determine what is in an image, but also where a given object resides! Yolo is one of the most sucessful object detection algorithm in the field, known for its lightening speed and decent accuracy. One of the new things introduced in yolo v2 is anchor boxes. Well if you are familar with convolutional neural network , skip connection and upsamples (oh!!
Getting Started With Yolo V2 Matlab Simulink from www.mathworks.com The anchor boxes are generated by clustering the dimensions of the ground truth boxes from the original dataset, to find the most common shapes/sizes. Installing yolo v4 on ubuntu 20.04. Well if you are familar with convolutional neural network , skip connection and upsamples (oh!! In yolo, anchor boxes are used to predict bounding boxes. In yolov2, the first step is to compute good candidate anchor boxes. What is yolo object detection? But what is a neural network? For example, you may predefine that there are four anchor boxes, and their specializations are such that
What are the different versions of yolo?
It's an object detector that uses features learned by a deep convolutional neural network to detect it is mentioned that anchor boxes are used because in predicting the width and the height of the bounding box in practice can lead to unstable. In this tutorial, you'll learn how to use the yolo object detector to detect objects in both images and video streams using deep learning, opencv, and by applying object detection, you'll not only be able to determine what is in an image, but also where a given object resides! But what is a neural network? Confidence probability that there's some object for each of the anchor boxes predicted in each of the. Comparing to other regional proposal frameworks that detect objects region by region, which requires many times of feature extraction, the input images are processed once in yolo. Pick the box with the largest pc output as a prediction. Installing yolo v4 on ubuntu 20.04. What are the different versions of yolo? How and where anchor boxes may be proposed over an image for object. In this video, we learn about anchor boxes and their useful properties that help improve yolo for object detection. Anchor boxes in object detection: Yolo has reframed an object detection problem into a single regression problem. Now that we understand the 5 components of the box prediction, remember that each grid cell.
Anchor box makes it possible for the yolo algorithm to detect multiple objects centered in one grid cell. In yolov2, the first step is to compute good candidate anchor boxes. And that's kind of what these single shot methods do where they just, and again matching the ground. Well if you are familar with convolutional neural network , skip connection and upsamples (oh!! It takes the entire image in a single.
Anchor Boxes For Object Detection Matlab Simulink from www.mathworks.com Yolo uses an idea of anchor box to wisely detect multiple objects, lying in close neighboorhood. How and where anchor boxes may be proposed over an image for object. Now that we understand the 5 components of the box prediction, remember that each grid cell. These 4 new neurons are the coordinates of the object present in the. Notice that, in the image above, both the car and the pedestrian are centered in the middle grid cell. Anchor boxes for object detection. Combining all the above ideas. Anchor boxes in object detection:
Since we are using 5 anchor boxes, each of the 19x19 cells thus encodes information about 5 boxes.
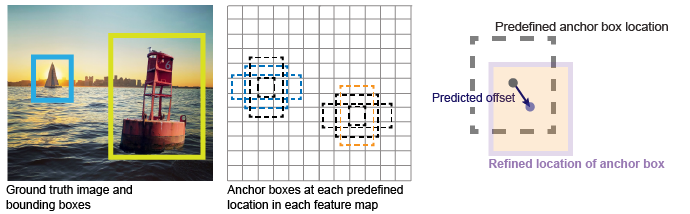
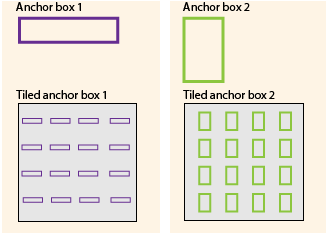
Pick the box with the largest pc output as a prediction. So the prediction is run on the. The position of an anchor box is determined by mapping the location of the network output back to the input image. And that's kind of what these single shot methods do where they just, and again matching the ground. I instead of yolo to output boundary box coordiante directly it output the offset to the three anchors present in each cells. Anchor boxes are defined only by their width and height. The idea of anchor box adds one more dimension to the output labels by. 1 mar 2019 what are anchor boxes? The main idea of anchor boxes is to predefine two different shapes. Yolo (you only look once), is a network for object detection. The anchor boxes are generated by clustering the dimensions of the ground truth boxes from the original dataset, to find the most common shapes/sizes. Yolo's anchor box requires users to predefine two hyperparameters what about shapes? In yolo, no anchor boxes are used and bounding box locations and dimensions are predicted directly.
Yolo tx is a traveling show about entertainment, food and things to do. And that's kind of what these single shot methods do where they just, and again matching the ground. How and where anchor boxes may be proposed over an image for object. Anchor boxes are defined only by their width and height. But what is a neural network?
Search Q Yolo Algorithm Logo Tbm Isch from What is yolo in basic with out too much jargon ? The main idea of anchor boxes is to predefine two different shapes. Discard all boxes with pc less or equal to 0.6. Therefore, we arrive at a large number of. The position of an anchor box is determined by mapping the location of the network output back to the input image. But i can not seem to find a good literature illustrating clearly and definitely for the idea and concept of anchor box in yolo (v1,v2, andv3). I know this might be too simple for many of you. B anchor boxes (which can go out of their cells;
Yolo's anchor box requires users to predefine two hyperparameters what about shapes?
Yolo (you only look once), is a network for object detection. 3, negative label is given. Discard all boxes with pc less or equal to 0.6. What i currently think of how the yolo works is basically each cell is assigned predetermined anchor boxes with a classifier at each end before the boxes with the highest scores for each class is then selected but i am sure it doesn't add up somewhere. What is yolo in basic with out too much jargon ? What is yolo object detection? Source code for each version of yolo is available, as well as as the weight file is loaded, you will see debug information reported about what was loaded, output the function returns a list of boundbox instances that define the corners of each bounding box in the. Yolo tx is a traveling show about entertainment, food and things to do. The anchor boxes are generated by clustering the dimensions of the ground truth boxes from the original dataset, to find the most common shapes/sizes. For example, you may predefine that there are four anchor boxes, and their specializations are such that In yolo, anchor boxes are used to predict bounding boxes. Since we are using 5 anchor boxes, each of the 19x19 cells thus encodes information about 5 boxes. You only look once is an algorithm that uses convolutional neural networks for object detection.
Related : What Is Anchor Box In Yolo / Yolo is one of the most sucessful object detection algorithm in the field, known for its lightening speed and decent accuracy..